Car Evaluation: Reglas de Asociación
joseangeldiazg
20/2/2018
1 Introducción al dataset
Para la práctica de reglas de asociación de la asignatura “Minería de Datos: Detección de Anomálias y Aprendizaje no Supervisado” se ha utilizado un dataset recuperado de la web de UCI que tiene ciertas características de coches y trata de evaluar los mismos en función de factores como su comodidad.
El dataset puede encontrarse en el siguiente enlace: https://archive.ics.uci.edu/ml/datasets/Car+Evaluation
Leemos los datos y construimos un dataframe, ya que estos vienen separados en data y names.
maint<-read.table("data/car.data", sep = ",")
names(car)<-c("precio-compra","precio-mantenimiento","puertas",
"pasajeros", "maletero", "seguridad", "clase")2 Análisis exploratorio
Vamos a comprobar si tenemos datos completos en los datos, ya que los valores perdidos siempre pueden causar problemas.
sum(is.na(car))## [1] 0Vemos que no hay valores perdidos por lo que el siguiente paso será ver de que tipo son nuestros datos, así como sus distribuciones para comenzar a hacernos una idea de que es lo que tenemos entre manos.
str(car)## 'data.frame': 1728 obs. of 7 variables:
## $ precio-compra : Factor w/ 4 levels "high","low","med",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ precio-mantenimiento: Factor w/ 4 levels "high","low","med",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ puertas : Factor w/ 4 levels "2","3","4","5more": 1 1 1 1 1 1 1 1 1 1 ...
## $ pasajeros : Factor w/ 3 levels "2","4","more": 1 1 1 1 1 1 1 1 1 2 ...
## $ maletero : Factor w/ 3 levels "big","med","small": 3 3 3 2 2 2 1 1 1 3 ...
## $ seguridad : Factor w/ 3 levels "high","low","med": 2 3 1 2 3 1 2 3 1 2 ...
## $ clase : Factor w/ 4 levels "acc","good","unacc",..: 3 3 3 3 3 3 3 3 3 3 ...Parece que todos son factores, por lo que no tendremos variables numéricas que partir en rangos que puedan ser caracterizados.
library(Hmisc)
describe(car)## car
##
## 7 Variables 1728 Observations
## ---------------------------------------------------------------------------
## precio-compra
## n missing distinct
## 1728 0 4
##
## Value high low med vhigh
## Frequency 432 432 432 432
## Proportion 0.25 0.25 0.25 0.25
## ---------------------------------------------------------------------------
## precio-mantenimiento
## n missing distinct
## 1728 0 4
##
## Value high low med vhigh
## Frequency 432 432 432 432
## Proportion 0.25 0.25 0.25 0.25
## ---------------------------------------------------------------------------
## puertas
## n missing distinct
## 1728 0 4
##
## Value 2 3 4 5more
## Frequency 432 432 432 432
## Proportion 0.25 0.25 0.25 0.25
## ---------------------------------------------------------------------------
## pasajeros
## n missing distinct
## 1728 0 3
##
## Value 2 4 more
## Frequency 576 576 576
## Proportion 0.333 0.333 0.333
## ---------------------------------------------------------------------------
## maletero
## n missing distinct
## 1728 0 3
##
## Value big med small
## Frequency 576 576 576
## Proportion 0.333 0.333 0.333
## ---------------------------------------------------------------------------
## seguridad
## n missing distinct
## 1728 0 3
##
## Value high low med
## Frequency 576 576 576
## Proportion 0.333 0.333 0.333
## ---------------------------------------------------------------------------
## clase
## n missing distinct
## 1728 0 4
##
## Value acc good unacc vgood
## Frequency 384 69 1210 65
## Proportion 0.222 0.040 0.700 0.038
## ---------------------------------------------------------------------------Respecto a las distribuciones, vemos que salvo la clase, final, donde tenemos mas coches catalogados como malos que buenos, todas las demás variables se distribuyen de manera homogénea y no balanceda. Esto nos beneficiará en el proceso de minado de reglas de asociación ya que tendremos representaciones homogéneas de los ítems. Dicho esto, estamos en posición de comenzar nuestro estudio de reglas de asociación e itemsets frecuentes.
3 Paso a base de datos transaccional
Para el proceso de obtención de reglas de asociación, la base de datos debe ser transaccional. Nuestro dataset, según lo estudiado en el punto anterior se presta a ello de manera fácil, por lo que no tendremos que preparar mucho los datos.
library(arules)
car.transactions <- as(car, "transactions")
summary(car.transactions)## transactions as itemMatrix in sparse format with
## 1728 rows (elements/itemsets/transactions) and
## 25 columns (items) and a density of 0.28
##
## most frequent items:
## clase=unacc pasajeros=2 pasajeros=4 pasajeros=more maletero=big
## 1210 576 576 576 576
## (Other)
## 8582
##
## element (itemset/transaction) length distribution:
## sizes
## 7
## 1728
##
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 7 7 7 7 7 7
##
## includes extended item information - examples:
## labels variables levels
## 1 precio-compra=high precio-compra high
## 2 precio-compra=low precio-compra low
## 3 precio-compra=med precio-compra med
##
## includes extended transaction information - examples:
## transactionID
## 1 1
## 2 2
## 3 34 Itemsets
En esta sección usaremos las transacciones de nuestro dataset para realizar un análisis de los itemsets. Para ello, nos centraremos en los itemsets frecuentes, maximales y cerrados.
El pauquete arules tiene una función muy útil que nos permite ver la distribución de ítems-frecuentes de manera gráfica para un valor determinado de soporte mínimo.
itemFrequencyPlot(car.transactions, support = 0.1, cex.names=0.8)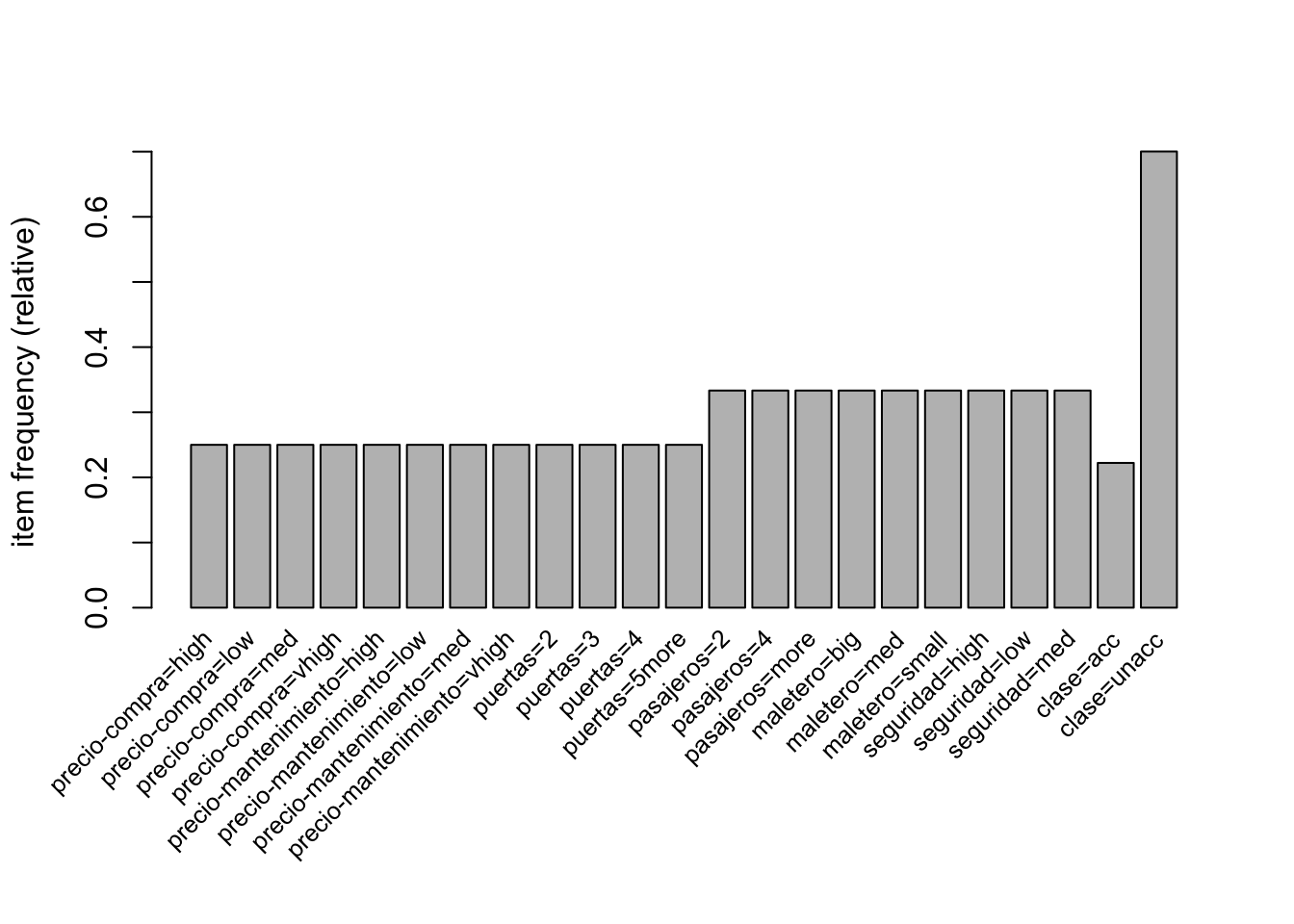
Si analizamos el anterior gráfico, podemos comprobar como solo clase=unacc, está presente en más de la mitad de las transacciones. Por otro lado, las demás variables se mantienen estables lo que gráficamente nos induce a pensar que es un dataset bastante artificial o confeccionado a conciencia para tener estas frecuencias de ítems. Cabe remarcar que no hay presencia de los ítems clase=good o clase=vgood, que a muy seguro tendrán valores de soporte menor de 0.1. Dado que estos ítems son muy interesantes para obtener información del problema, ya podemos remarcar que el valor de soporte para la obtención de las reglas deberá ser menor de 0.1. Vamos a comprobar que esta premisa es así, representando el mismo gráfico pero con menos soporte.
itemFrequencyPlot(car.transactions, support = 0.01, cex.names=0.8)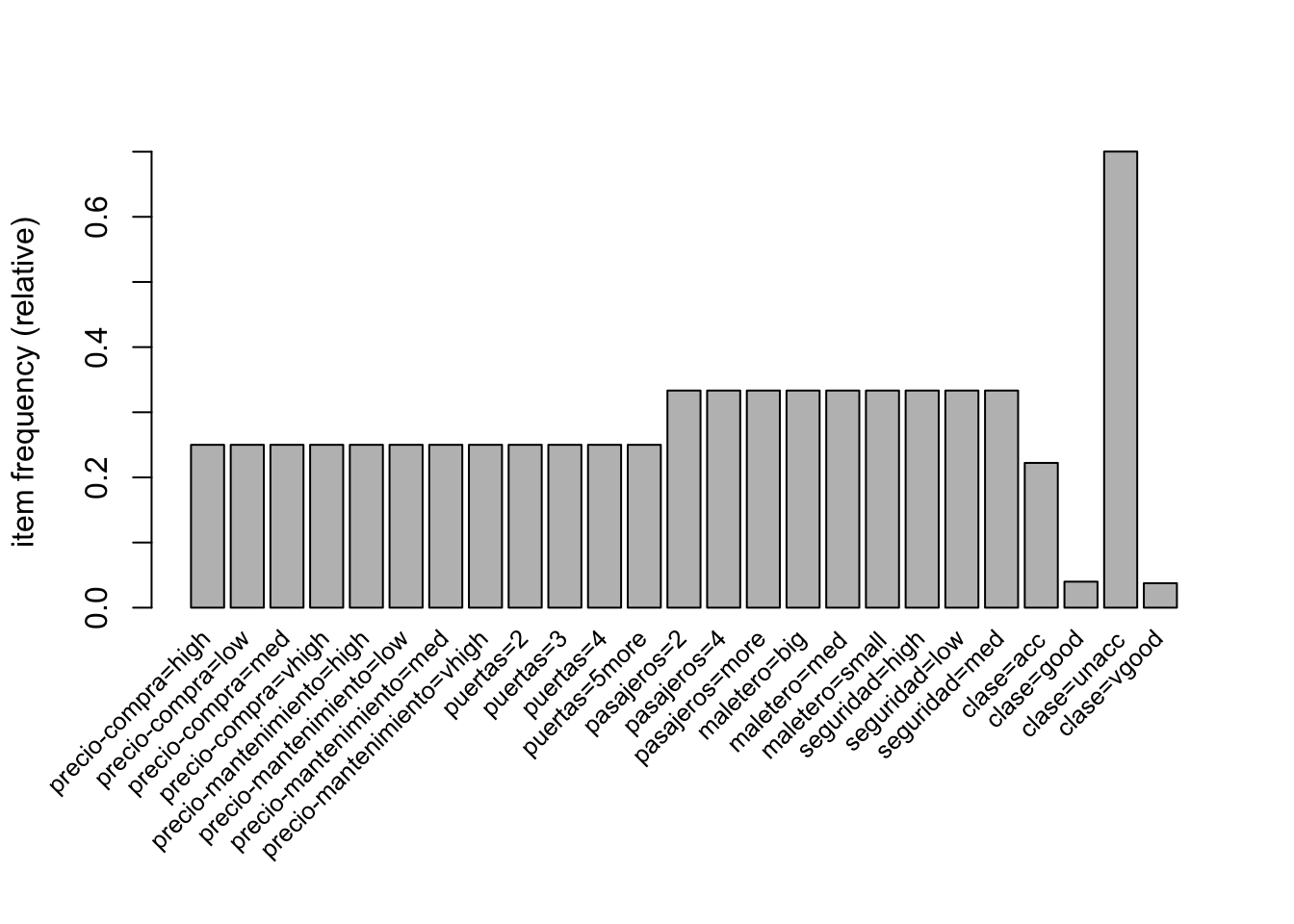
En el anterior gráfico podemos apreciar como han aparecido dos nuevas columnas, que reprentan los ítems clase=good y clase=vgood lo que nos lleva a concluir por tanto que los valores de soporte de estos ítems en función al resto son muy bajos, algo que los convierte en muy interesantes y dignos de estudio ya que además resentan a dos clases aceptables del problema.
Vamos a obtener el algoritmo apriori, para obtener los itemsets frecuentes y analizarlos con más detalle atendiendo a sus medidas.
iCar <- apriori(car.transactions, parameter = list(support = 0.01, target="frequent", minlen=1))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## NA 0.1 1 none FALSE TRUE 5 0.01 1
## maxlen target ext
## 10 frequent itemsets FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 17
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[25 item(s), 1728 transaction(s)] done [0.00s].
## sorting and recoding items ... [25 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4 done [0.00s].
## writing ... [2291 set(s)] done [0.00s].
## creating S4 object ... done [0.00s].#Ordenamos los ítems por soporte descendente
iCar <- sort(iCar, by="support")Hemos generado un total de 2291 itemsets frecuentes. Vamos a ver cuales son estos, usando el comando inspect.
#Inspeccionamos los 100 primeros
inspect(head(iCar, n=50))## items support count
## [1] {clase=unacc} 0.7002315 1210
## [2] {pasajeros=more} 0.3333333 576
## [3] {pasajeros=4} 0.3333333 576
## [4] {maletero=big} 0.3333333 576
## [5] {maletero=med} 0.3333333 576
## [6] {seguridad=high} 0.3333333 576
## [7] {seguridad=med} 0.3333333 576
## [8] {seguridad=low} 0.3333333 576
## [9] {maletero=small} 0.3333333 576
## [10] {pasajeros=2} 0.3333333 576
## [11] {seguridad=low,clase=unacc} 0.3333333 576
## [12] {pasajeros=2,clase=unacc} 0.3333333 576
## [13] {maletero=small,clase=unacc} 0.2604167 450
## [14] {precio-compra=vhigh} 0.2500000 432
## [15] {precio-compra=med} 0.2500000 432
## [16] {precio-compra=high} 0.2500000 432
## [17] {precio-mantenimiento=low} 0.2500000 432
## [18] {precio-mantenimiento=med} 0.2500000 432
## [19] {precio-mantenimiento=high} 0.2500000 432
## [20] {puertas=5more} 0.2500000 432
## [21] {puertas=4} 0.2500000 432
## [22] {puertas=3} 0.2500000 432
## [23] {puertas=2} 0.2500000 432
## [24] {precio-mantenimiento=vhigh} 0.2500000 432
## [25] {precio-compra=low} 0.2500000 432
## [26] {maletero=med,clase=unacc} 0.2268519 392
## [27] {clase=acc} 0.2222222 384
## [28] {maletero=big,clase=unacc} 0.2129630 368
## [29] {precio-compra=vhigh,clase=unacc} 0.2083333 360
## [30] {precio-mantenimiento=vhigh,clase=unacc} 0.2083333 360
## [31] {seguridad=med,clase=unacc} 0.2065972 357
## [32] {puertas=2,clase=unacc} 0.1886574 326
## [33] {precio-compra=high,clase=unacc} 0.1875000 324
## [34] {pasajeros=more,clase=unacc} 0.1863426 322
## [35] {precio-mantenimiento=high,clase=unacc} 0.1817130 314
## [36] {pasajeros=4,clase=unacc} 0.1805556 312
## [37] {puertas=3,clase=unacc} 0.1736111 300
## [38] {puertas=5more,clase=unacc} 0.1689815 292
## [39] {puertas=4,clase=unacc} 0.1689815 292
## [40] {seguridad=high,clase=unacc} 0.1603009 277
## [41] {precio-compra=med,clase=unacc} 0.1550926 268
## [42] {precio-mantenimiento=low,clase=unacc} 0.1550926 268
## [43] {precio-mantenimiento=med,clase=unacc} 0.1550926 268
## [44] {precio-compra=low,clase=unacc} 0.1493056 258
## [45] {seguridad=high,clase=acc} 0.1180556 204
## [46] {pasajeros=4,clase=acc} 0.1145833 198
## [47] {pasajeros=more,maletero=big} 0.1111111 192
## [48] {pasajeros=more,maletero=med} 0.1111111 192
## [49] {pasajeros=more,seguridad=high} 0.1111111 192
## [50] {pasajeros=more,seguridad=med} 0.1111111 192Si nos centraramos solo en los ítemsets frecuentes, ya podríamos obtener información relevante del dataset e incluso hacer algunas “predicciones” en un hipotético caso de toma de decisiones, como por ejemplo el set de ítems [29] {precio-compra=vhigh,clase=unacc} en contra de lo que podríamos llegar a pensar aparecen bastantes veces en el dataset que si el precio de compra es muy caro, la clase será la peor, por lo que ya podríamos casi asegurar que con mucha probabilidad que un coche sea evaluado como bueno o malo vendrá dado por otros motivos en lugar de un precio caro.
Otro set de ítems interesantes, podría ser el [12] {pasajeros=2,clase=unacc}, aquí estamos claramente frente a coches deportivos de dos plazas que en un gran número de casos, son asignados a la peor clase, por lo que esto nos deja saber que probablemente lo que tenemos entre manos son evaluaciones que nada tienen que ver con lujos o grandes motores sino con coches serviciales y destinados al uso diario.
Si quisieramos acotar y seguir analizando los ítemsets frecuentes, podríamos usar rangos definidos por las variables minlen y maxlen para definir cuantos ítems queremos que formen los sets.
iCar <- apriori(car.transactions, parameter = list(support = 0.01,
target="frequent",
minlen=2,
maxlen=4))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## NA 0.1 1 none FALSE TRUE 5 0.01 2
## maxlen target ext
## 4 frequent itemsets FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 17
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[25 item(s), 1728 transaction(s)] done [0.00s].
## sorting and recoding items ... [25 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4## Warning in apriori(car.transactions, parameter = list(support = 0.01,
## target = "frequent", : Mining stopped (maxlen reached). Only patterns up to
## a length of 4 returned!## done [0.00s].
## writing ... [2266 set(s)] done [0.00s].
## creating S4 object ... done [0.00s].#Ordenamos los ítems por soporte descendente
iCar <- sort(iCar, by="support")
#Mostramos a modo de ejemplo los 20 primeros
inspect(head(iCar, n=20))## items support count
## [1] {seguridad=low,clase=unacc} 0.3333333 576
## [2] {pasajeros=2,clase=unacc} 0.3333333 576
## [3] {maletero=small,clase=unacc} 0.2604167 450
## [4] {maletero=med,clase=unacc} 0.2268519 392
## [5] {maletero=big,clase=unacc} 0.2129630 368
## [6] {precio-compra=vhigh,clase=unacc} 0.2083333 360
## [7] {precio-mantenimiento=vhigh,clase=unacc} 0.2083333 360
## [8] {seguridad=med,clase=unacc} 0.2065972 357
## [9] {puertas=2,clase=unacc} 0.1886574 326
## [10] {precio-compra=high,clase=unacc} 0.1875000 324
## [11] {pasajeros=more,clase=unacc} 0.1863426 322
## [12] {precio-mantenimiento=high,clase=unacc} 0.1817130 314
## [13] {pasajeros=4,clase=unacc} 0.1805556 312
## [14] {puertas=3,clase=unacc} 0.1736111 300
## [15] {puertas=5more,clase=unacc} 0.1689815 292
## [16] {puertas=4,clase=unacc} 0.1689815 292
## [17] {seguridad=high,clase=unacc} 0.1603009 277
## [18] {precio-compra=med,clase=unacc} 0.1550926 268
## [19] {precio-mantenimiento=low,clase=unacc} 0.1550926 268
## [20] {precio-mantenimiento=med,clase=unacc} 0.1550926 268Estos parámetros anteriores pueden ser muy útiles en grandes conjuntos de datos donde la explosión de itemsets sea muy grande. En nuestro caso, dejaremos los parámetros por defecto dado que a simple vista podemos manejarlos todos sin muchas complicaciones. Obtendremos por tanto los de todos los tamaños y crearemos un gráfico de barras para ver su distribución.
iCar <- apriori(car.transactions, parameter = list(support = 0.01, target="frequent"))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## NA 0.1 1 none FALSE TRUE 5 0.01 1
## maxlen target ext
## 10 frequent itemsets FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 17
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[25 item(s), 1728 transaction(s)] done [0.00s].
## sorting and recoding items ... [25 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4 done [0.00s].
## writing ... [2291 set(s)] done [0.00s].
## creating S4 object ... done [0.00s].barplot(table(size(iCar)), xlab="itemset size", ylab="count")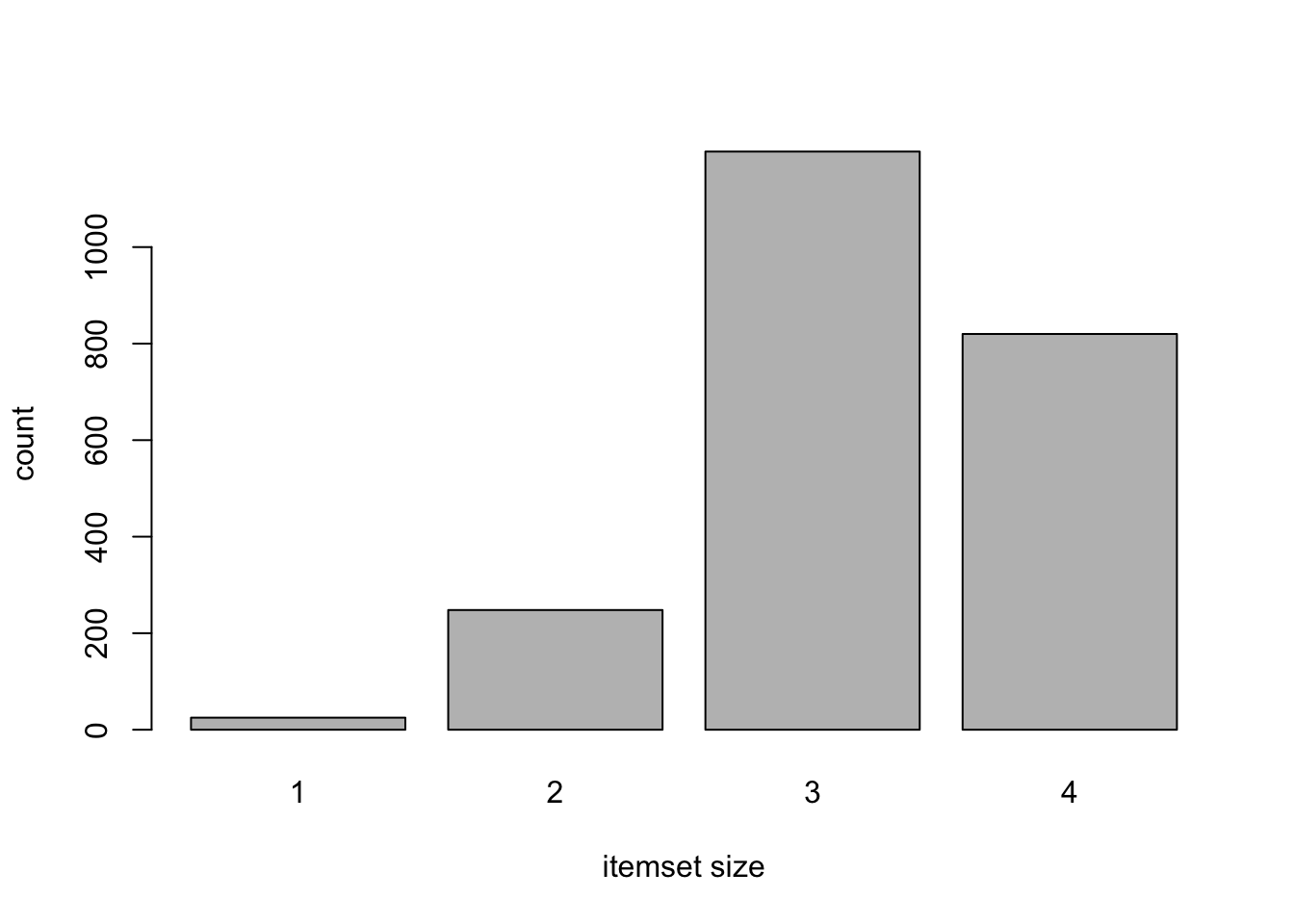
En el anterior gráfico podemos ver como la mayor parte de los ítemsets frecuentes son de tamaño 3 y 4, por lo que todo apunta a que podremos obtener buenas reglas y de un tamaño aceptable para sacar conclusiones en nuestro proceso de evaluación de coches.
En esta caso, los ítems no son muchos, por lo que podríamos quedarnos con ellos sin problema. Por otro lado, en caso de tener una set de ítems mayor, podríamos usar los ítems maximales o cerrados. Para obtener estos, el paquete apriori nos ofrece funciones fáciles de usar como sigue:
- Maximales:
imaxCar <- iCar[is.maximal(iCar)]
imaxCar## set of 1000 itemsetsinspect(head(sort(imaxCar, by="support")))## items support count
## [1] {pasajeros=more,
## maletero=big,
## seguridad=low,
## clase=unacc} 0.03703704 64
## [2] {pasajeros=more,
## maletero=med,
## seguridad=low,
## clase=unacc} 0.03703704 64
## [3] {pasajeros=more,
## maletero=small,
## seguridad=low,
## clase=unacc} 0.03703704 64
## [4] {pasajeros=4,
## maletero=big,
## seguridad=low,
## clase=unacc} 0.03703704 64
## [5] {pasajeros=4,
## maletero=med,
## seguridad=low,
## clase=unacc} 0.03703704 64
## [6] {pasajeros=4,
## maletero=small,
## seguridad=low,
## clase=unacc} 0.03703704 64- Cerrados:
icloCar <- iCar[is.closed(iCar)]
icloCar## set of 1950 itemsetsinspect(head(sort(icloCar, by="support")))## items support count
## [1] {clase=unacc} 0.7002315 1210
## [2] {pasajeros=more} 0.3333333 576
## [3] {pasajeros=4} 0.3333333 576
## [4] {maletero=big} 0.3333333 576
## [5] {maletero=med} 0.3333333 576
## [6] {seguridad=high} 0.3333333 576Una vez obtenidos todos, vamos a representar con un gráfico el número de ítems de cada clase:
barplot( c(frequent=length(iCar), closed=length(icloCar),
maximal=length(imaxCar)), ylab="count", xlab="itemsets")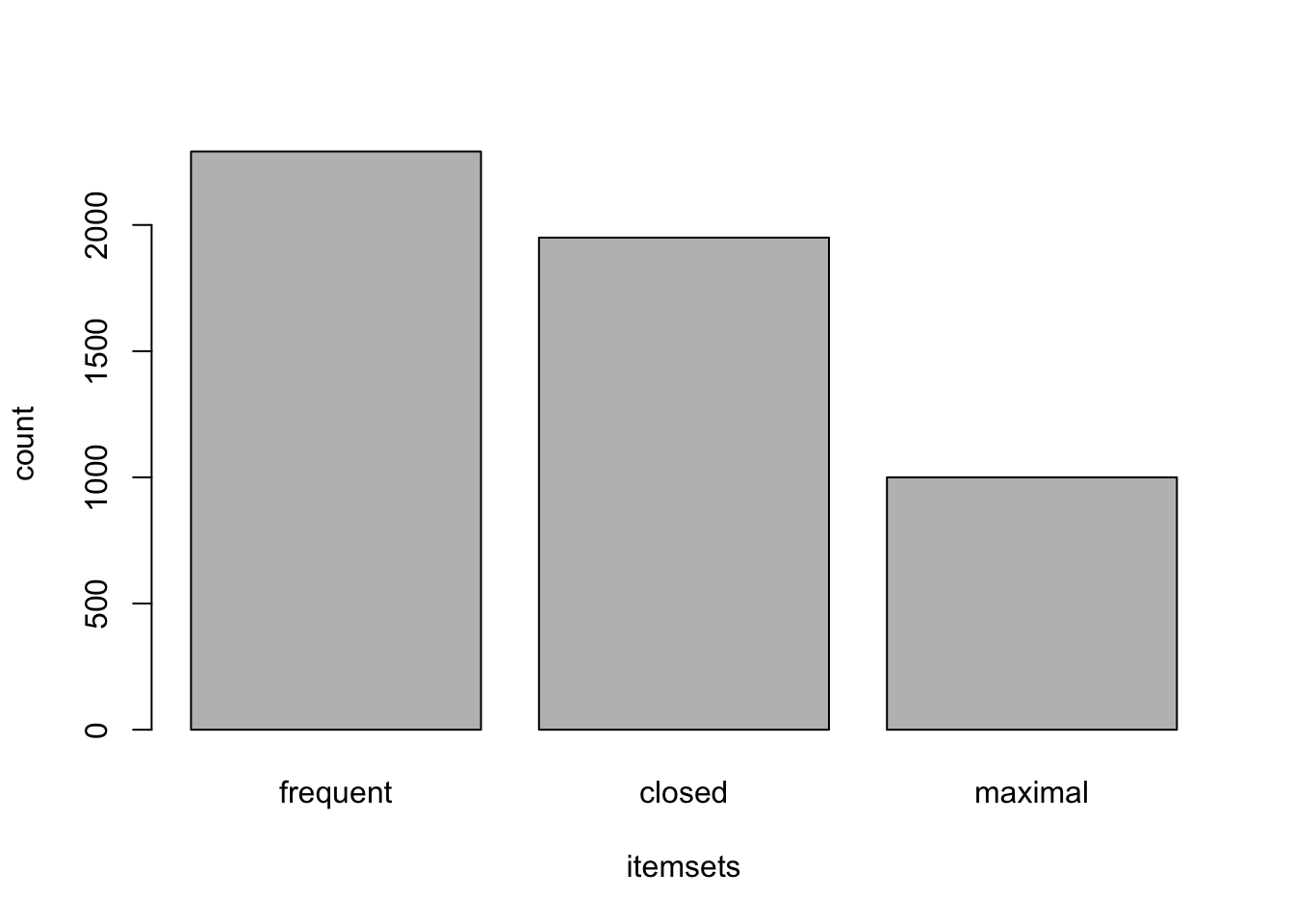
El gráfico muestra lo que según la teoría cabe esperar y es que los maximales, son los menos abundantes, frente a cerrados y frecuentes que siempre se dan de la mano, aunque siempre son estos segundos algo más abundantes en el dominio del problema.
Dado que tenemos todos estos conjuntos vamos a comprobar las premisas de eficiencia que instan a usar unos u otros, que en casi todos los casos se traducen en reducción del espacio que ocupan. Por ello, vamos a obtener los tamaños de cada uno de los objetos.
object.size(iCar)## 85384 bytesobject.size(icloCar)## 82496 bytesobject.size(imaxCar)## 49240 bytesEn este caso, los tamaños son insignificantes, pero si extrapolaramos los datos a un problema real, que incluso pudiera ser catalogado como Big Data, tener una representación que nos permitiera ahorrar espacio de casi un 50%, (como es el caso de los ítems maximales en nuestro problema), seguramente los beneficios fuerán mayores y necesarios de tener en cuenta.
5 Reglas de asociación
En este punto usaremos el método apriori para obtener las reglas de asociación. Esta es la parte esencial de la práctica y trataremos de evaluar cuando un coche es bueno y cuando es malo mediante estos métodos.
rules <- apriori(car, parameter = list(support = 0.01, confidence = 0.8, minlen = 2))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.8 0.1 1 none FALSE TRUE 5 0.01 2
## maxlen target ext
## 10 rules FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 17
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[25 item(s), 1728 transaction(s)] done [0.00s].
## sorting and recoding items ... [25 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4 done [0.00s].
## writing ... [415 rule(s)] done [0.00s].
## creating S4 object ... done [0.00s].rules## set of 415 rulesHemos obtenido 415 reglas de asociación, por lo que al no ser muchas, podremos estudiarlas sin mucha complejidad. Aún así, antes de entrar en el análisis vamos a eliminar las reglas redundantes, para no caer en el error de analizar dos veces la misma regla.
rulesSorted = sort(rules, by = "confidence")
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPruned <- rulesSorted[!redundant]
rulesPruned## set of 38 rulesReglas no redundantes, aparecen solo 38. Esto ha simplificado el problema aún más, tanto que incluso podríamos llegar a pensar que el dataset no es apropiado ya que no ofrece muchas caracteristicas descriptivas.
Antes de entrar en el análisis de las reglas, en un dominio donde el número de estas sea muy abundante puede ser de especial utilidad obtener visualmente información sobre el número de reglas y la bondaz de las mismas. Para ello, podemos apoyarnos en gráficos:
library(arulesViz)
plot(rulesPruned, method="two-key plot")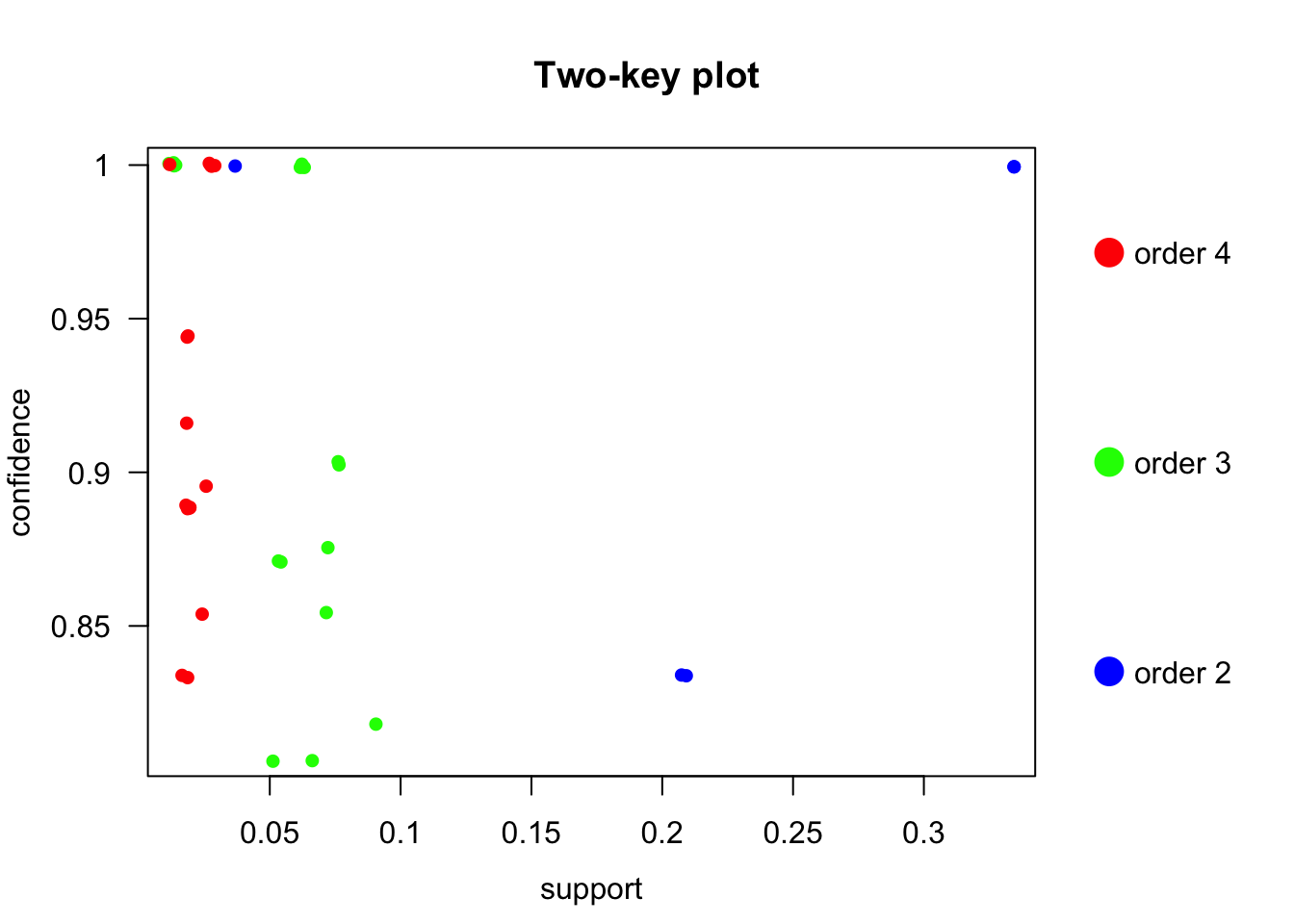
En este gráfico, podemos ver las reglas obtenidas, el tamaño de las mismas y como se situan en función del soporte y la confianza. Algo muy util incluso para ver ciertos patrones, como por ejemplo, comprobar como las reglas de mayor número de ítems se situan con valores menores de soporte. Una vez vista la distribucion de las reglas obtenidas vamos a inspeccionarlas manualmente:
inspect(rulesPruned)## lhs rhs support confidence lift count
## [1] {clase=vgood} => {seguridad=high} 0.03761574 1.0000000 3.000000 65
## [2] {seguridad=low} => {clase=unacc} 0.33333333 1.0000000 1.428099 576
## [3] {pasajeros=2} => {clase=unacc} 0.33333333 1.0000000 1.428099 576
## [4] {precio-compra=med,
## clase=good} => {precio-mantenimiento=low} 0.01331019 1.0000000 4.000000 23
## [5] {precio-mantenimiento=med,
## clase=good} => {precio-compra=low} 0.01331019 1.0000000 4.000000 23
## [6] {maletero=big,
## clase=good} => {seguridad=med} 0.01388889 1.0000000 3.000000 24
## [7] {maletero=small,
## clase=good} => {seguridad=high} 0.01215278 1.0000000 3.000000 21
## [8] {precio-compra=vhigh,
## precio-mantenimiento=high} => {clase=unacc} 0.06250000 1.0000000 1.428099 108
## [9] {precio-compra=vhigh,
## precio-mantenimiento=vhigh} => {clase=unacc} 0.06250000 1.0000000 1.428099 108
## [10] {precio-compra=high,
## precio-mantenimiento=vhigh} => {clase=unacc} 0.06250000 1.0000000 1.428099 108
## [11] {precio-compra=high,
## maletero=small,
## clase=acc} => {seguridad=high} 0.01215278 1.0000000 3.000000 21
## [12] {precio-compra=vhigh,
## maletero=small,
## seguridad=med} => {clase=unacc} 0.02777778 1.0000000 1.428099 48
## [13] {precio-compra=high,
## maletero=small,
## seguridad=med} => {clase=unacc} 0.02777778 1.0000000 1.428099 48
## [14] {puertas=2,
## pasajeros=more,
## maletero=small} => {clase=unacc} 0.02777778 1.0000000 1.428099 48
## [15] {precio-mantenimiento=vhigh,
## maletero=small,
## seguridad=med} => {clase=unacc} 0.02777778 1.0000000 1.428099 48
## [16] {precio-compra=vhigh,
## puertas=2,
## maletero=small} => {clase=unacc} 0.01967593 0.9444444 1.348760 34
## [17] {precio-mantenimiento=vhigh,
## puertas=2,
## maletero=small} => {clase=unacc} 0.01967593 0.9444444 1.348760 34
## [18] {precio-compra=high,
## puertas=2,
## maletero=small} => {clase=unacc} 0.01909722 0.9166667 1.309091 33
## [19] {precio-compra=vhigh,
## maletero=small} => {clase=unacc} 0.07523148 0.9027778 1.289256 130
## [20] {precio-mantenimiento=vhigh,
## maletero=small} => {clase=unacc} 0.07523148 0.9027778 1.289256 130
## [21] {puertas=2,
## maletero=small,
## seguridad=med} => {clase=unacc} 0.02488426 0.8958333 1.279339 43
## [22] {precio-compra=vhigh,
## puertas=2,
## maletero=med} => {clase=unacc} 0.01851852 0.8888889 1.269421 32
## [23] {precio-compra=vhigh,
## puertas=2,
## seguridad=med} => {clase=unacc} 0.01851852 0.8888889 1.269421 32
## [24] {precio-mantenimiento=high,
## puertas=2,
## maletero=small} => {clase=unacc} 0.01851852 0.8888889 1.269421 32
## [25] {precio-mantenimiento=vhigh,
## puertas=2,
## maletero=med} => {clase=unacc} 0.01851852 0.8888889 1.269421 32
## [26] {precio-mantenimiento=vhigh,
## puertas=2,
## seguridad=med} => {clase=unacc} 0.01851852 0.8888889 1.269421 32
## [27] {puertas=2,
## maletero=small} => {clase=unacc} 0.07291667 0.8750000 1.249587 126
## [28] {precio-compra=vhigh,
## puertas=2} => {clase=unacc} 0.05439815 0.8703704 1.242975 94
## [29] {precio-mantenimiento=vhigh,
## puertas=2} => {clase=unacc} 0.05439815 0.8703704 1.242975 94
## [30] {precio-compra=high,
## maletero=small} => {clase=unacc} 0.07118056 0.8541667 1.219835 123
## [31] {precio-mantenimiento=high,
## maletero=small,
## seguridad=med} => {clase=unacc} 0.02372685 0.8541667 1.219835 41
## [32] {precio-compra=vhigh} => {clase=unacc} 0.20833333 0.8333333 1.190083 360
## [33] {precio-mantenimiento=vhigh} => {clase=unacc} 0.20833333 0.8333333 1.190083 360
## [34] {precio-compra=high,
## puertas=2,
## maletero=med} => {clase=unacc} 0.01736111 0.8333333 1.190083 30
## [35] {precio-compra=high,
## puertas=2,
## seguridad=med} => {clase=unacc} 0.01736111 0.8333333 1.190083 30
## [36] {maletero=small,
## seguridad=med} => {clase=unacc} 0.09085648 0.8177083 1.167769 157
## [37] {precio-compra=high,
## puertas=2} => {clase=unacc} 0.05034722 0.8055556 1.150413 87
## [38] {precio-mantenimiento=high,
## maletero=small} => {clase=unacc} 0.06712963 0.8055556 1.150413 116Si analizamos las relglas obtenidas, parece que hemos tenido un claro sesgo hacia nuestra clase mayoritaria y obtenemos reglas aceptables que nos llevan a saber cuando un coche no es apropiado. Deberemos afinar un poco más el proceso de obtención de reglas para obtener informacion que realmente aporte valor. Esto podrá hacerse probablemente, realizando un estudio basado en generalización o jerarquización de reglas.
Aún así, aunque este set de reglas no nos ayuda mucho con nuestra premisa inicial de ver cuando un coche será evaluado como bueno, sí que nos ayuda para obtener información acerca de cuando un determinado vehiculo tendrá evaluación negativa, ademas de darnos información curiosa aunque ciertamente trivial como la regla * [1] {clase=vgood} => {seguridad=high} * que nos indica que si la evaluación del vehículo es muy buena, la seguridad será muy alta. Por otro lado, volvemos a tener un claro ejemplo en como los coches ‘deportivos’ serán evaluados como malos en este problema, ya que tenemos reglas del tipo 16 => {clase=unacc}, donde ahora sin ningun tipo de duda estamos ante este tipo de coches, precios altos, 2 puertas y maleteros pequeños implicarán clases malas.
Dado que lo que nos interesa es ver cuando será una evaluaciona aceptable y cuando no, en los próximos puntos realizaremos un análisis más exhaustivo para intentar obtener aún mejor información y representarla graficamente.
7 Enfoques avanzados
7.1 Reglas generalizadas o gerarquicas
Dado que los resultados vistos anteriormente no son muy buenos, se nos presenta la posibilidad de hacer las siguientes generalizaciones para ver si obtenemos mejores resultados:
*Clase=unacc -> Clase=MalaEvaluacion
*Clase=acc, Clase=good y Clase=vgood -> Clase=BuenaEvaluacion
Para realizar este paso, primero copiaremos en dataset (para evitar modificar el original), cambiaremos estos valores y tras ello obtendremos de nuevo las reglas.
cargeneralizazo<-car
cargeneralizazo$clase<-ifelse(cargeneralizazo$clase=="unacc","MalaEvaluacion","BuenaEvaluacion")
cargeneralizazo$clase<-as.factor(cargeneralizazo$clase)
head(cargeneralizazo,5)## precio-compra precio-mantenimiento puertas pasajeros maletero seguridad
## 1 vhigh vhigh 2 2 small low
## 2 vhigh vhigh 2 2 small med
## 3 vhigh vhigh 2 2 small high
## 4 vhigh vhigh 2 2 med low
## 5 vhigh vhigh 2 2 med med
## clase
## 1 MalaEvaluacion
## 2 MalaEvaluacion
## 3 MalaEvaluacion
## 4 MalaEvaluacion
## 5 MalaEvaluacionUna vez hecho el cambio, obtendremos nuestras transacciones y reglas de asociación.
cargeneralizazo.transactions <- as(cargeneralizazo, "transactions")
rules.generalizadas <- apriori(cargeneralizazo.transactions,
parameter = list(support = 0.01, confidence = 0.8, minlen = 2))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.8 0.1 1 none FALSE TRUE 5 0.01 2
## maxlen target ext
## 10 rules FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 17
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[23 item(s), 1728 transaction(s)] done [0.00s].
## sorting and recoding items ... [23 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4 done [0.00s].
## writing ... [421 rule(s)] done [0.00s].
## creating S4 object ... done [0.00s].rules.generalizadas## set of 421 rulesParece que obtenemos alguna reglas más que anterioremente. Vamos a filtrarlas por no redundantes e intentar obtener información de ellas.
rulesSorted = sort(rules.generalizadas, by = "confidence")
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPruned <- rulesSorted[!redundant]
inspect(rulesPruned)## lhs rhs support confidence lift count
## [1] {seguridad=low} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [2] {pasajeros=2} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [3] {precio-compra=vhigh,
## precio-mantenimiento=high} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [4] {precio-compra=vhigh,
## precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [5] {precio-compra=high,
## precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [6] {precio-compra=vhigh,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [7] {precio-compra=med,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [8] {precio-compra=high,
## maletero=small,
## clase=BuenaEvaluacion} => {seguridad=high} 0.01215278 1.0000000 3.000000 21
## [9] {precio-compra=high,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [10] {precio-mantenimiento=low,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [11] {precio-mantenimiento=med,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [12] {puertas=2,
## maletero=small,
## clase=BuenaEvaluacion} => {pasajeros=4} 0.01041667 1.0000000 3.000000 18
## [13] {puertas=2,
## pasajeros=more,
## maletero=small} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [14] {precio-mantenimiento=vhigh,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [15] {precio-compra=low,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [16] {precio-compra=vhigh,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01967593 0.9444444 1.348760 34
## [17] {precio-mantenimiento=vhigh,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01967593 0.9444444 1.348760 34
## [18] {precio-compra=med,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [19] {precio-compra=high,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01909722 0.9166667 1.309091 33
## [20] {precio-mantenimiento=low,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [21] {precio-mantenimiento=med,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [22] {precio-compra=low,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [23] {precio-compra=vhigh,
## maletero=small} => {clase=MalaEvaluacion} 0.07523148 0.9027778 1.289256 130
## [24] {precio-mantenimiento=vhigh,
## maletero=small} => {clase=MalaEvaluacion} 0.07523148 0.9027778 1.289256 130
## [25] {puertas=2,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02488426 0.8958333 1.279339 43
## [26] {precio-compra=vhigh,
## puertas=2,
## maletero=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [27] {precio-compra=vhigh,
## puertas=2,
## seguridad=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [28] {precio-mantenimiento=high,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [29] {precio-mantenimiento=vhigh,
## puertas=2,
## maletero=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [30] {precio-mantenimiento=vhigh,
## puertas=2,
## seguridad=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [31] {puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.07291667 0.8750000 1.249587 126
## [32] {precio-compra=low,
## pasajeros=4,
## seguridad=med} => {clase=BuenaEvaluacion} 0.02430556 0.8750000 2.918919 42
## [33] {precio-compra=vhigh,
## puertas=2} => {clase=MalaEvaluacion} 0.05439815 0.8703704 1.242975 94
## [34] {precio-mantenimiento=vhigh,
## puertas=2} => {clase=MalaEvaluacion} 0.05439815 0.8703704 1.242975 94
## [35] {precio-compra=high,
## maletero=small} => {clase=MalaEvaluacion} 0.07118056 0.8541667 1.219835 123
## [36] {precio-mantenimiento=high,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02372685 0.8541667 1.219835 41
## [37] {precio-compra=vhigh} => {clase=MalaEvaluacion} 0.20833333 0.8333333 1.190083 360
## [38] {precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.20833333 0.8333333 1.190083 360
## [39] {precio-compra=high,
## puertas=2,
## maletero=med} => {clase=MalaEvaluacion} 0.01736111 0.8333333 1.190083 30
## [40] {precio-compra=high,
## puertas=2,
## seguridad=med} => {clase=MalaEvaluacion} 0.01736111 0.8333333 1.190083 30
## [41] {precio-compra=low,
## pasajeros=more,
## seguridad=med} => {clase=BuenaEvaluacion} 0.02314815 0.8333333 2.779923 40
## [42] {maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.09085648 0.8177083 1.167769 157
## [43] {pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.09027778 0.8125000 2.710425 156
## [44] {puertas=5more,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02256944 0.8125000 2.710425 39
## [45] {puertas=4,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02256944 0.8125000 2.710425 39
## [46] {puertas=3,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02256944 0.8125000 2.710425 39
## [47] {pasajeros=more,
## maletero=med,
## seguridad=high} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [48] {pasajeros=4,
## maletero=big,
## seguridad=med} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [49] {pasajeros=more,
## maletero=big,
## seguridad=high} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [50] {pasajeros=more,
## maletero=big,
## seguridad=med} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [51] {precio-compra=high,
## puertas=2} => {clase=MalaEvaluacion} 0.05034722 0.8055556 1.150413 87
## [52] {precio-mantenimiento=high,
## maletero=small} => {clase=MalaEvaluacion} 0.06712963 0.8055556 1.150413 116Parece que nuestro proceso de generalización de reglas ha surtido efecto y tenemos ya presencia de clase=BuenaEvaluacion en los consecuentes, que es la premisa que buscamos, es decir, ver cuando un coche será bien evaluado en función de sus características. Una función interesante para evaluar las reglas estará también en encontrar aquellas que están relacioandas con determinados ítems. Por ejemplo vamos a construir dos sets de reglas, uno para los de la clase MalaEvaluación y otro para los de la clase BuenaEvaluación.
rules.malaeval<- apriori (cargeneralizazo, parameter=list(supp=0.01,conf = 0.8),
appearance =list (default="lhs",rhs="clase=MalaEvaluacion"),
control = list (verbose=F))
rules.buenaeval<- apriori (cargeneralizazo, parameter=list(supp=0.01,conf = 0.8),
appearance =list (default="lhs",rhs="clase=BuenaEvaluacion"),
control = list (verbose=F))Ahora limpiaremos los sets de reglas redundantes.
#Mala evaluación
rulesSorted = sort(rules.malaeval, by = "confidence")
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPrunedMala <- rulesSorted[!redundant]
#Buena evaluación
rulesSorted = sort(rules.buenaeval, by = "confidence")
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPrunedBuena <- rulesSorted[!redundant] Por último, mostramos las reglas y las estudiamos:
inspect(rulesPrunedBuena)## lhs rhs support confidence lift count
## [1] {precio-compra=low,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [2] {precio-compra=med,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [3] {precio-mantenimiento=low,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [4] {precio-mantenimiento=med,
## pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02777778 1.0000000 3.335907 48
## [5] {precio-compra=low,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [6] {precio-compra=med,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [7] {precio-mantenimiento=low,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [8] {precio-mantenimiento=med,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02546296 0.9166667 3.057915 44
## [9] {precio-compra=low,
## pasajeros=4,
## seguridad=med} => {clase=BuenaEvaluacion} 0.02430556 0.8750000 2.918919 42
## [10] {precio-compra=low,
## pasajeros=more,
## seguridad=med} => {clase=BuenaEvaluacion} 0.02314815 0.8333333 2.779923 40
## [11] {pasajeros=4,
## seguridad=high} => {clase=BuenaEvaluacion} 0.09027778 0.8125000 2.710425 156
## [12] {puertas=5more,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02256944 0.8125000 2.710425 39
## [13] {puertas=4,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02256944 0.8125000 2.710425 39
## [14] {puertas=3,
## pasajeros=more,
## seguridad=high} => {clase=BuenaEvaluacion} 0.02256944 0.8125000 2.710425 39
## [15] {pasajeros=4,
## maletero=big,
## seguridad=med} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [16] {pasajeros=more,
## maletero=big,
## seguridad=high} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [17] {pasajeros=more,
## maletero=big,
## seguridad=med} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [18] {pasajeros=more,
## maletero=med,
## seguridad=high} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52Parece que nuestro proceso ha tenido utilidad y tenemos un buen set de reglas con valores bastante aceptables de medidas de bondaz. Vamos a estudiar algunas reglas interesantes:
- [16] {pasajeros=more,maletero=big,seguridad=high} => {clase=BuenaEvaluacion}
- [17] {pasajeros=more,maletero=big,seguridad=med} => {clase=BuenaEvaluacion}
- [18] {pasajeros=more,maletero=med,seguridad=high} => {clase=BuenaEvaluacion}
Estas tres reglas, confirman la teoria que teníamos anteriormente de que en el proceso de evaluación se están teniendo en cuenta coches serviciales frente a coches lujosos, bonitos o rápidos. Al estudiar las reglas anteriores, es evidente, que estamos ante coches familiares o del tipo monovolumen y los cuales son bastante bien valorados a pesar de que otros factores como el tamaño o la seguridad pueda tomar valores dispares.
Otra regla interesante, puede ser la 15 => {clase=BuenaEvaluacion}, donde vemos como la evaluación de un hipotético coche se permite descensos en seguridad pos de mayor tamaño.
Por otro lado, hay también reglas triviales que no nos dicen nada como pueden ser 1 => {clase=BuenaEvaluacion} y 3 => {clase=BuenaEvaluacion} donde podemos corroborar la típica expresión popular del “bueno, bonito y barato”, pero que no aporta valor ninguno.
También, puede obtenerse información por ausencia de reglas, es decir, podemos ver que no hay ninguna regla cuyo antecedente contenga el ítem seguridad=low, por lo que a muy seguro, este sea un ítem que determinará en la mayoría de los casos una mala evaluación. Para comprobar esta premisa, por último, vamos a estudiar las reglas para clase=MalaEvaluacion.
inspect(rulesPrunedMala)## lhs rhs support confidence lift count
## [1] {seguridad=low} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [2] {pasajeros=2} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [3] {precio-compra=vhigh,
## precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [4] {precio-compra=vhigh,
## precio-mantenimiento=high} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [5] {precio-compra=high,
## precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [6] {precio-compra=vhigh,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [7] {precio-mantenimiento=vhigh,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [8] {puertas=2,
## pasajeros=more,
## maletero=small} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [9] {precio-compra=high,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02777778 1.0000000 1.428099 48
## [10] {precio-compra=vhigh,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01967593 0.9444444 1.348760 34
## [11] {precio-mantenimiento=vhigh,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01967593 0.9444444 1.348760 34
## [12] {precio-compra=high,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01909722 0.9166667 1.309091 33
## [13] {precio-compra=vhigh,
## maletero=small} => {clase=MalaEvaluacion} 0.07523148 0.9027778 1.289256 130
## [14] {precio-mantenimiento=vhigh,
## maletero=small} => {clase=MalaEvaluacion} 0.07523148 0.9027778 1.289256 130
## [15] {puertas=2,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02488426 0.8958333 1.279339 43
## [16] {precio-compra=vhigh,
## puertas=2,
## maletero=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [17] {precio-compra=vhigh,
## puertas=2,
## seguridad=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [18] {precio-mantenimiento=vhigh,
## puertas=2,
## maletero=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [19] {precio-mantenimiento=vhigh,
## puertas=2,
## seguridad=med} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [20] {precio-mantenimiento=high,
## puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.01851852 0.8888889 1.269421 32
## [21] {puertas=2,
## maletero=small} => {clase=MalaEvaluacion} 0.07291667 0.8750000 1.249587 126
## [22] {precio-compra=vhigh,
## puertas=2} => {clase=MalaEvaluacion} 0.05439815 0.8703704 1.242975 94
## [23] {precio-mantenimiento=vhigh,
## puertas=2} => {clase=MalaEvaluacion} 0.05439815 0.8703704 1.242975 94
## [24] {precio-compra=high,
## maletero=small} => {clase=MalaEvaluacion} 0.07118056 0.8541667 1.219835 123
## [25] {precio-mantenimiento=high,
## maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.02372685 0.8541667 1.219835 41
## [26] {precio-compra=vhigh} => {clase=MalaEvaluacion} 0.20833333 0.8333333 1.190083 360
## [27] {precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.20833333 0.8333333 1.190083 360
## [28] {precio-compra=high,
## puertas=2,
## maletero=med} => {clase=MalaEvaluacion} 0.01736111 0.8333333 1.190083 30
## [29] {precio-compra=high,
## puertas=2,
## seguridad=med} => {clase=MalaEvaluacion} 0.01736111 0.8333333 1.190083 30
## [30] {maletero=small,
## seguridad=med} => {clase=MalaEvaluacion} 0.09085648 0.8177083 1.167769 157
## [31] {precio-compra=high,
## puertas=2} => {clase=MalaEvaluacion} 0.05034722 0.8055556 1.150413 87
## [32] {precio-mantenimiento=high,
## maletero=small} => {clase=MalaEvaluacion} 0.06712963 0.8055556 1.150413 116De primeras podemos comprobar la hipótesis planteada anteriormente, ya que la priemera regla obtenida nos indica que {seguridad=low} => {clase=MalaEvaluacion}, en un gran número de los casos.
También es interesante como puertas=2 parece ser el factor predominante en las reglas que causen mala evaluación por lo que esta información podría ser utilizada por ejemplo en una compañia automovilística que fuera a lanzar un nuevo coche en un determinado sector y sabría que la evaluación que los usarios harán de el, aunque los tamaños sean del coche en sí talla media-grande, será con mucha probabilidad mala si no se remedia el factor de las puertas.
Aunque, como hemos podido comprobar, las reglas de asociación son muy descriptivas y fácilmente entendibles, en algunos casos puede ser complicado obtener información de las mismas, por lo que usaremos gráficos para ver si podemos obtener o representar de una manera más amable los resultados.
plot(rulesPrunedBuena[1:10], method="graph")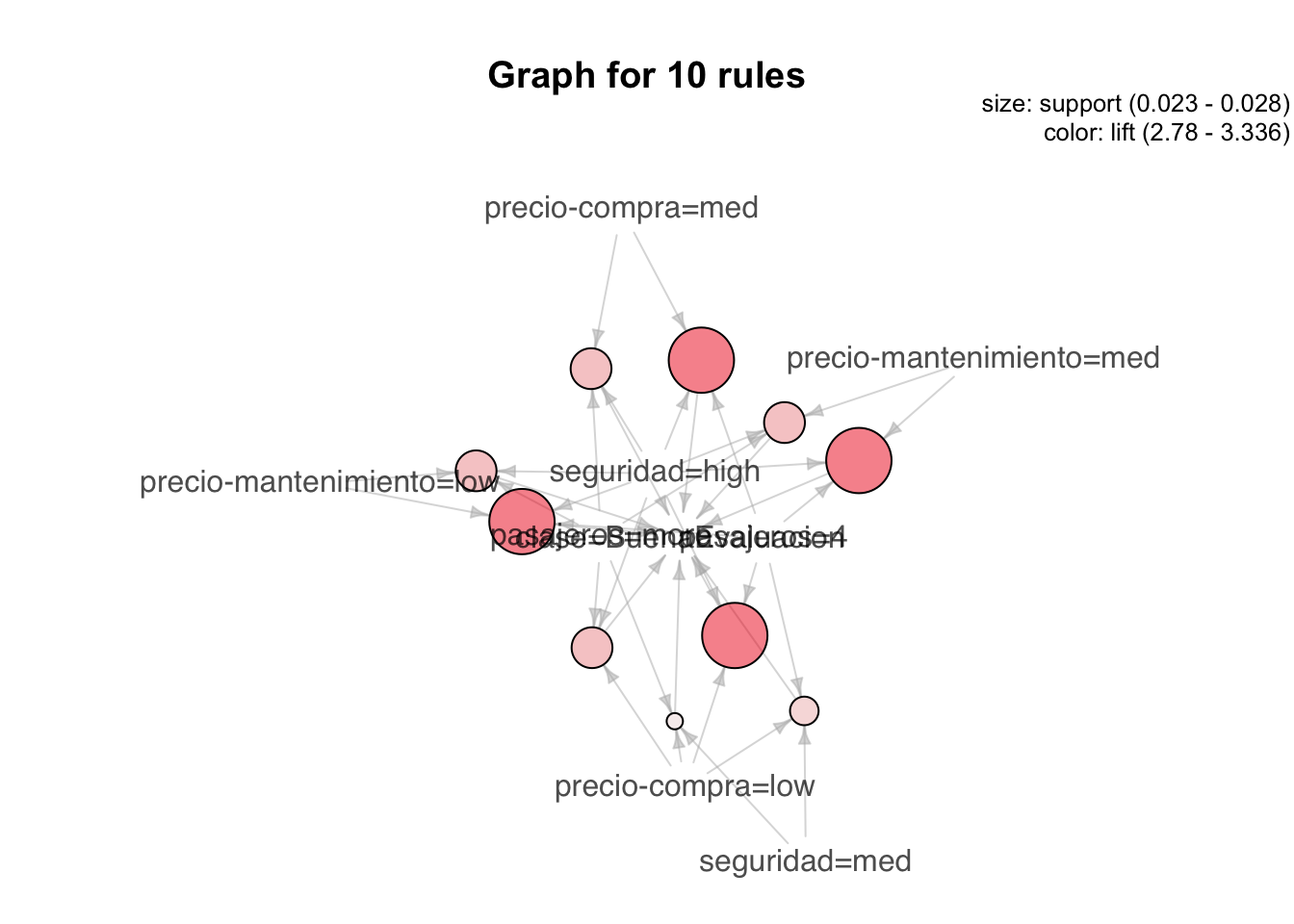
Este gráfico se representa de manera poco útil debido al solapamient de los nodos, hubs y aristas. Por ello deberemos utilizar la opción engine=interactive, donde podremos mover los nodos y las artistas del gráfico a nuestra manera obteniendo una mejor representación como puede ser:
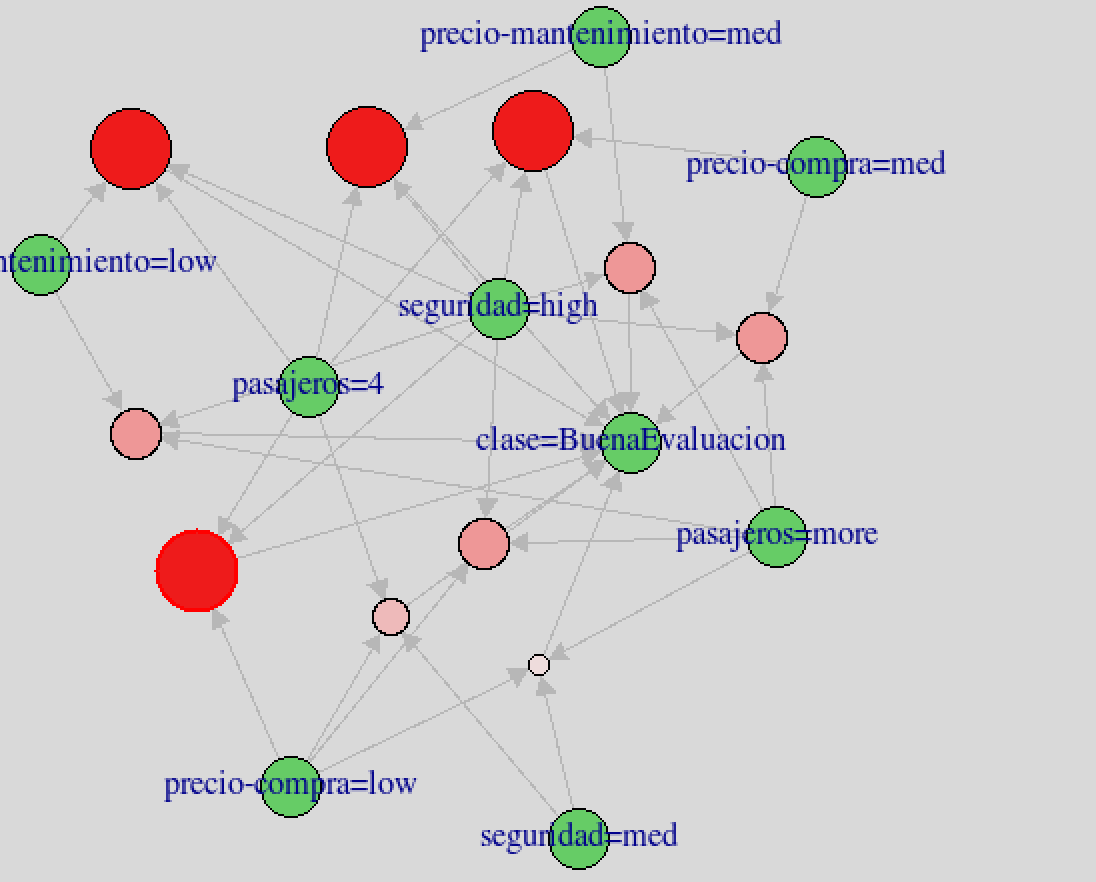
Representación en grafo con engine=interactive
A modo de ejemplo, en este gráfico podemos ver como si pasajeros=more, seuridad=med y precio-compra=low, entonces, la clase será buena.
7.2 Ítems negados y Análisis por grupos
Por último realizaremos un estudio de ítems negados y análisis por grupos. Para ello, tendremos que negar los ítems de nuestra base de datos en una especie de dummificación, por lo que podremos usar el paquete dummies para facilitar el proceso y construir nuestro dataset. Dado que la explosión de ítems puede ser muy elevada, solo lo realizaremos con dos variables, seguridad y puertas.
library(dummies)
puertas<-dummy(cargeneralizazo$puertas)
seguridad<-dummy(cargeneralizazo$seguridad)
#Creamos el dataset
negados<-cbind("precio-compra"=as.character(cargeneralizazo$`precio-compra`),
"precio-mantenimiento"=as.character(cargeneralizazo$`precio-mantenimiento`),
puertas, "pasajeros"=as.character(cargeneralizazo$pasajeros),
"maletero"=as.character(cargeneralizazo$maletero), seguridad,
"clase"=as.character(cargeneralizazo$clase))
negados<-as.data.frame(negados)Ahora tendremos que pasar los 1 y los 0 de las variables creadas a true o false tras lo cual, obtendremos los datos en un dataframe de factores para que las transacciones puedan obtenerse de manera correcta.
negados[,c(3:6,9:11)]<-ifelse(negados[,c(3:6,9:11)]==1,TRUE,FALSE)
#Por último pasamos a factor los datos y obtenemos las transacciones
negados<-apply(negados, 2, as.factor)
negados<-as.data.frame(negados)
str(negados)## 'data.frame': 1728 obs. of 12 variables:
## $ precio-compra : Factor w/ 4 levels "high","low","med",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ precio-mantenimiento: Factor w/ 4 levels "high","low","med",..: 4 4 4 4 4 4 4 4 4 4 ...
## $ NA2 : Factor w/ 2 levels " TRUE","FALSE": 1 1 1 1 1 1 1 1 1 1 ...
## $ NA3 : Factor w/ 2 levels " TRUE","FALSE": 2 2 2 2 2 2 2 2 2 2 ...
## $ NA4 : Factor w/ 2 levels " TRUE","FALSE": 2 2 2 2 2 2 2 2 2 2 ...
## $ NA5more : Factor w/ 2 levels " TRUE","FALSE": 2 2 2 2 2 2 2 2 2 2 ...
## $ pasajeros : Factor w/ 3 levels "2","4","more": 1 1 1 1 1 1 1 1 1 2 ...
## $ maletero : Factor w/ 3 levels "big","med","small": 3 3 3 2 2 2 1 1 1 3 ...
## $ NAhigh : Factor w/ 2 levels " TRUE","FALSE": 2 2 1 2 2 1 2 2 1 2 ...
## $ NAlow : Factor w/ 2 levels " TRUE","FALSE": 1 2 2 1 2 2 1 2 2 1 ...
## $ NAmed : Factor w/ 2 levels " TRUE","FALSE": 2 1 2 2 1 2 2 1 2 2 ...
## $ clase : Factor w/ 2 levels "BuenaEvaluacion",..: 2 2 2 2 2 2 2 2 2 2 ...Obtenemos las reglas de asociación (aumentando un poco el soporte, ya que de otro modo el número de estas es muy grande) y las limpiamos ya que ahora puede haber una gran representación de reglas que tengan el mismo significado.
negados <- as(negados, "transactions")
rules.negadas <- apriori(negados, parameter = list(support = 0.03,
confidence = 0.8,
minlen = 2))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.8 0.1 1 none FALSE TRUE 5 0.03 2
## maxlen target ext
## 10 rules FALSE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 51
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[30 item(s), 1728 transaction(s)] done [0.00s].
## sorting and recoding items ... [30 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4 5 6 7 8 done [0.02s].
## writing ... [18858 rule(s)] done [0.01s].
## creating S4 object ... done [0.01s].rules.negadas## set of 18858 rulesVemos como el número de reglas si que se ha disparado en este caso, obteniendo un total de 18858 reglas. Vamos a limpiarlas para no perder el tiempo con reglas similares.
rulesSortedNegadas = sort(rules.negadas, by = "confidence")
subsetMatrix <- is.subset(rulesSortedNegadas, rulesSortedNegadas)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPrunedNegadas <- rulesSortedNegadas[!redundant]
rulesPrunedNegadas## set of 236 rulesDado que nuevamente, tenemos set de reglas de tamaño suficientemente grande como para no poder ser analizadas todas manualmente, obtendremos solo aquellas con las clases en los consecuentes, ya que de otro modo, hay muchas reglas que meten ruido y no son para nada interesantes como estas{puertas4= TRUE} => {puertas2=FALSE}, {puertas4= TRUE}=>{puertas5more=FALSE}, {puertas4= TRUE} => {puertas3=FALSE} y las demás combinaciones posibles de reglas de este tipo.
rules.malaeval.negados<- apriori(negados, parameter=list(supp=0.03,conf = 0.8),
appearance =list (default="lhs",rhs="clase=MalaEvaluacion"),
control = list (verbose=F))
rules.buenaeval.negados<- apriori(negados, parameter=list(supp=0.03,conf = 0.8),
appearance =list (default="lhs",rhs="clase=BuenaEvaluacion"),
control = list (verbose=F))
#Mala evaluación
rulesSorted = sort(rules.malaeval.negados, by = "confidence")
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPrunedMalaNegados <- rulesSorted[!redundant]
rulesPrunedMalaNegados## set of 138 rules#Buena evaluación
rulesSorted = sort(rules.buenaeval.negados, by = "confidence")
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
subsetMatrix[lower.tri(subsetMatrix, diag=TRUE)] <- FALSE
redundant <- colSums(subsetMatrix, na.rm=TRUE) >= 1
rulesPrunedBuenaNegados <- rulesSorted[!redundant]
rulesPrunedBuenaNegados## set of 33 rulesPor último, analizamos las reglas:
inspect(rulesPrunedBuenaNegados)## lhs rhs support confidence lift count
## [1] {precio-compra=low,
## NA2=FALSE,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03993056 0.9583333 3.196911 69
## [2] {precio-compra=low,
## NA2=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03935185 0.9444444 3.150579 68
## [3] {precio-compra=low,
## NA3=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03935185 0.9444444 3.150579 68
## [4] {precio-compra=low,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.05208333 0.9375000 3.127413 90
## [5] {precio-compra=med,
## NA2=FALSE,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03819444 0.9166667 3.057915 66
## [6] {precio-mantenimiento=low,
## NA2=FALSE,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03819444 0.9166667 3.057915 66
## [7] {precio-mantenimiento=med,
## NA2=FALSE,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03819444 0.9166667 3.057915 66
## [8] {precio-compra=med,
## NA2=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03703704 0.8888889 2.965251 64
## [9] {precio-compra=med,
## NA3=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03703704 0.8888889 2.965251 64
## [10] {precio-mantenimiento=low,
## NA2=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03703704 0.8888889 2.965251 64
## [11] {precio-mantenimiento=low,
## NA3=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03703704 0.8888889 2.965251 64
## [12] {precio-mantenimiento=med,
## NA2=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03703704 0.8888889 2.965251 64
## [13] {precio-mantenimiento=med,
## NA3=FALSE,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03703704 0.8888889 2.965251 64
## [14] {precio-compra=low,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04861111 0.8750000 2.918919 84
## [15] {precio-compra=med,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04861111 0.8750000 2.918919 84
## [16] {precio-mantenimiento=low,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04861111 0.8750000 2.918919 84
## [17] {precio-mantenimiento=med,
## pasajeros=4,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04861111 0.8750000 2.918919 84
## [18] {precio-compra=med,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04629630 0.8333333 2.779923 80
## [19] {precio-mantenimiento=low,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04629630 0.8333333 2.779923 80
## [20] {precio-mantenimiento=med,
## pasajeros=more,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04629630 0.8333333 2.779923 80
## [21] {pasajeros=4,
## NAhigh= TRUE} => {clase=BuenaEvaluacion} 0.09027778 0.8125000 2.710425 156
## [22] {pasajeros=4,
## maletero=big,
## NAmed= TRUE} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [23] {pasajeros=more,
## maletero=big,
## NAmed= TRUE} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [24] {pasajeros=more,
## maletero=med,
## NAhigh= TRUE} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [25] {pasajeros=more,
## maletero=big,
## NAhigh= TRUE} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [26] {NA2=FALSE,
## pasajeros=more,
## NAhigh= TRUE} => {clase=BuenaEvaluacion} 0.06770833 0.8125000 2.710425 117
## [27] {pasajeros=4,
## maletero=big,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.06018519 0.8125000 2.710425 104
## [28] {pasajeros=more,
## maletero=big,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.06018519 0.8125000 2.710425 104
## [29] {pasajeros=4,
## NAlow=FALSE,
## NAmed=FALSE} => {clase=BuenaEvaluacion} 0.09027778 0.8125000 2.710425 156
## [30] {pasajeros=more,
## maletero=med,
## NAlow=FALSE,
## NAmed=FALSE} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52
## [31] {NA2=FALSE,
## pasajeros=more,
## maletero=med,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.04513889 0.8125000 2.710425 78
## [32] {NA2=FALSE,
## pasajeros=more,
## NAlow=FALSE,
## NAmed=FALSE} => {clase=BuenaEvaluacion} 0.06770833 0.8125000 2.710425 117
## [33] {NA2=FALSE,
## NA3=FALSE,
## pasajeros=4,
## maletero=med,
## NAlow=FALSE} => {clase=BuenaEvaluacion} 0.03009259 0.8125000 2.710425 52Básicamente todas las reglas que tenemos entre manos tienen ítems negados que corresponden a seguridadlow=FALSE, algo que era de esperar. Por otro lado, podemos comprobar la potencia de este método en reglas como {puertas2=FALSE,puertas3=FALSE,pasajeros=4,maletero=med,seguridadlow=FALSE} => {clase=BuenaEvaluacion} donde gracias a los ítems negados en una sola regla podemos deducir 4 reglas interesantes que serían:
- {puertas=4,pasajeros=4,maletero=med,seguridad=med} => {clase=BuenaEvaluacion}
- {puertas=4,pasajeros=4,maletero=med,seguridad=high} => {clase=BuenaEvaluacion}
- {puertas=5more,pasajeros=4,maletero=med,seguridad=med} => {clase=BuenaEvaluacion}
- {puertas=5more,pasajeros=4,maletero=med,seguridad=high} => {clase=BuenaEvaluacion}
inspect(head(rulesPrunedMalaNegados,10))## lhs rhs support confidence lift count
## [1] {NAlow= TRUE} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [2] {pasajeros=2} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [3] {precio-compra=vhigh,
## precio-mantenimiento=high} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [4] {precio-compra=high,
## precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [5] {precio-compra=vhigh,
## precio-mantenimiento=vhigh} => {clase=MalaEvaluacion} 0.06250000 1.0000000 1.428099 108
## [6] {NAhigh=FALSE,
## NAmed=FALSE} => {clase=MalaEvaluacion} 0.33333333 1.0000000 1.428099 576
## [7] {precio-compra=high,
## maletero=small,
## NAhigh=FALSE} => {clase=MalaEvaluacion} 0.05555556 1.0000000 1.428099 96
## [8] {precio-mantenimiento=vhigh,
## maletero=small,
## NAhigh=FALSE} => {clase=MalaEvaluacion} 0.05555556 1.0000000 1.428099 96
## [9] {precio-compra=vhigh,
## maletero=small,
## NAhigh=FALSE} => {clase=MalaEvaluacion} 0.05555556 1.0000000 1.428099 96
## [10] {NA2= TRUE,
## maletero=small,
## NAhigh=FALSE} => {clase=MalaEvaluacion} 0.05266204 0.9479167 1.353719 91Al inspeccionar estas reglas, nos encontramos con uno de los grandes problemas de los ítems negados y es que son muy redundantes, por ejemplo si nos fijamos en las reglas {seguridadlow= TRUE} => {clase=MalaEvaluacion} y {seguridadhigh=FALSE,seguridadmed=FALSE} => {clase=MalaEvaluacion}, tenemos entre manos la misma regla de asociacón ya que la negación de seguridadhigh y seguridadmed implica, aprobación de seguridadlow. Este problema, es muy complicado de ver e implica el tener conocimiento del problema, ya que un analista que no supiera que esta variable solo puede tomar 3 valores podría concluir en un error de análisis.
Por último, puede resultar interesante el análisis de reglas por grupos o parejas. Esto nos puede ayudar a descartar reglas o información que de primeras parecia importante pero en realidad no lo son. En nuestro caso, tenemos ítems negados en algunas variables y ademas tenemos la variable clase, que también podría ser negada, teniendo en cuenta que clase=MalaEvaluacion es la negacion de {clase=BuenaEvaluacion}.
Teniendo esto en cuenta, vamos a comprobar nuestra premisa de que las seguridadlow=TRUE implican siempre MalaEvaluacion:
Tenemos esta regla: {seguridadlow=TRUE} => {clase=MalaEvaluacion} es fuerte y ofrece buenos soportes de soporte y confianza, si las analizamos en conjunción con reglas que tengan {clase=BuenaEvaluacion} deberemos encontrar siempre en los consecuentes seguridadlow=FALSE, es decir, la negación de la anterior. Analizando el dataset podremos encontra varias reglas que cumplen esto como pueden ser:
- {precio-mantenimiento=low,pasajeros=4,seguridadlow=FALSE} => {clase=BuenaEvaluacion}
- {precio-mantenimiento=med,pasajeros=4,seguridadlow=FALSE} => {clase=BuenaEvaluacion}
En base a esto podríamos afirmar que en base a un análisis por grupos seguridadlow=TRUE implica siempre MalaEvaluacion.
8 Resumen
Tras este estudio de reglas de asociación llevado a cabo, hemos podido constatar la potencia de las reglas como método descriptivo para la obtención de información en grandes conjuntos de datos. La potencia del método es tal, que incluso podremos obtener información relevante y catalogar la muestra sin tener nada de informaciÓn del tipo de datos ni su procedencia. Para ilustrar esto podemos tomar por ejemplo las conclusiones obtenidas de esta práctica, donde tras obtener ítems frecuentes y reglas ya sabiamos que aunque estamos evaluando coches, el tamaño y el nivel de utilidad de los coches sería mas relevante que aspectos de diseño.
Queda demostrada también la potencia de las reglas de asociación en el ámbito de la minería de datos y nos hace comprender mejor, porque son uno de los métodos que desde su nacimiento han sido más estudiados y extendidos a diferentes problemas.